В России употребление URL в официальных документах регулируется ГОСТ Р 7.0.5-2008 «Библиографическая ссылка. Общие требования и правила составления».
Английская аббревиатура URL расшифровывается как Uniform Resource Locator, что в переводе на русский означает «унифицированный указатель ресурса». Впервые URL стал применяться в 1990 году. Слава его изобретения принадлежит создателю Всемирной паутины — Тиму Бернерсу-Ли.
Что такое URL
Определить URL-адрес веб-страницы просто — он показан в адресной строке браузера. Оттуда его можно скопировать, кликнув по адресной строке правой кнопкой мыши (при этом адрес выделяется) и в контекстном меню выбрав команду «Копировать».
Чтобы скопировать адрес отдельного изображения на странице, нужно кликнуть правой кнопкой мыши по картинке и выбрать пункт «Копировать адрес изображения» или «Копировать URL картинки» (в разных браузерах название команды может отличаться).
Для копирования адреса документа в контекстном меню ведущей к нему ссылки следует выбрать команду «Копировать адрес ссылки».
Во всех случаях URL окажется в буфера обмена, откуда его можно вставить в адресную строку браузера, переслать в сообщении либо вставить в текстовый документ.
Зарегистрируйте ваш домен в популярной зоне
От 99 рублей в год
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
URL (или URL адрес) – это форма уникального адреса конкретного веб-ресурса в сети Интернет. Он может ссылаться на веб-сайт, какой-то индивидуальный документ или изображение. Пользователю Интернета нужно вставить этот код в поле поиска, чтобы найти нужный сайт, документ, папку или изображение. На простом языке это означает следующее: благодаря URL адресу пользователь узнает информацию о том, где находятся нужные ему данные.
URL адрес – это аббревиатура, обозначающая термин Universal Resource Locator (всеобщий указатель ресурса). Он содержит ссылку на сервер, который является хранилищем искомого ресурса. В общем, URL это путь с сервера к последнему устройству (которое является платформой работы пользователя). Верхний элемент – это сервер хранения ресурсов, самый низкий – пользовательское устройство. Все точки между этими двумя являются дополнительными серверами.
Найдите проблемные URL
Проведите аудит вашего сайт и получите полный список страниц, где URL больше 100 символов
URL (адрес)
URL (от англ. Uniform Resource Locator – унифицированный указатель ресурса), стандартизированный способ записи адреса ресурса (веб-страницы, файла и т. п.) в сети Интернет, определяющий его местонахождение и способ доступа к нему.
URL введён Т. Бернерсом-Ли в 1990 г. (см. также Всемирная паутина).
Помимо URL, в сети Интернет используется также способ стандартизированной идентификации абстрактного или физического ресурса – единообразное название (имя) ресурса (англ. Uniform Resource Name – URN), в котором ключевой информацией является имя ресурса, возможно никак не связанное с местом хранения и способом доступа к этому ресурсу, например Международный стандартный книжный номер (англ. International Standard Book Number – ISBN).
URL и URN являются составными частями более общей концепции единообразного (унифицированного) идентификатора ресурса (англ. Uniform Resource Identifier – URI). На рубеже 1990–2000-х гг. появляются разъяснения в официальных документах Интернета RFC (в частности, RFC 3305), предполагающие дальнейшее широкое использование URI, а затем возникают и соответствующие стандарты (см., например, RFC 3986), тем самым делая URL менее формальным, хотя и по-прежнему широко используемым на практике термином.
Опубликовано 24 августа 2022 г. в 10:34 (GMT+3). Последнее обновление 6 июля 2023 г. в 06:47 (GMT+3).
URL (Uniform Resource Locator или УРЛ (Единый указатель ресурсов)) — это стандартизированный формат адреса для определения местоположения ресурса в сети Интернет. Он представляет собой последовательность символов, которая указывает на местонахождение конкретного ресурса, такого как:
Структура URL формируется из:

URL позволяет идентифицировать уникальное местоположение ресурса (сайта, веб-страницы, картинки, документа) в сети Интернет и обеспечивает механизм доступа к этому ресурсу с помощью веб-браузеров или других приложений.
В веб-разработке и интернет-маркетинге выделяют, так называемые, статические, динамические и человекопонятные URL’ы:
Пример человекопонятного URL:
This article discusses Uniform Resource Locators (URLs), explaining what they are and how they’re structured.
Summary
URL stands for Uniform Resource Locator. A URL is nothing more than the address of a given unique resource on the Web. In theory, each valid URL points to a unique resource. Such resources can be an HTML page, a CSS document, an image, etc. In practice, there are some exceptions, the most common being a URL pointing to a resource that no longer exists or that has moved. As the resource represented by the URL and the URL itself are handled by the Web server, it is up to the owner of the web server to carefully manage that resource and its associated URL.
Anatomy of a URL
Here are some examples of URLs:
Any of those URLs can be typed into your browser’s address bar to tell it to load the associated page (resource).
Note: You might think of a URL like a regular postal mail address: the scheme represents the postal service you want to use, the domain name is the city or town, and the port is like the zip code; the path represents the building where your mail should be delivered; the parameters represent extra information such as the number of the apartment in the building; and, finally, the anchor represents the actual person to whom you’ve addressed your mail.
Scheme
The first part of the URL is the scheme, which indicates the protocol that the browser must use to request the resource (a protocol is a set method for exchanging or transferring data around a computer network). Usually for websites the protocol is HTTPS or HTTP (its unsecured version). Addressing web pages requires one of these two, but browsers also know how to handle other schemes such as mailto: (to open a mail client), so don’t be surprised if you see other protocols.
Note: The separator between the scheme and authority is ://. The colon separates the scheme from the next part of the URL, while // indicates that the next part of the URL is the authority.
Path to resource
/path/to/myfile.html is the path to the resource on the Web server. In the early days of the Web, a path like this represented a physical file location on the Web server. Nowadays, it is mostly an abstraction handled by Web servers without any physical reality.
Parameters
?key1=value1&key2=value2 are extra parameters provided to the Web server. Those parameters are a list of key/value pairs separated with the & symbol. The Web server can use those parameters to do extra stuff before returning the resource. Each Web server has its own rules regarding parameters, and the only reliable way to know if a specific Web server is handling parameters is by asking the Web server owner.
Anchor
#SomewhereInTheDocument is an anchor to another part of the resource itself. An anchor represents a sort of «bookmark» inside the resource, giving the browser the directions to show the content located at that «bookmarked» spot. On an HTML document, for example, the browser will scroll to the point where the anchor is defined; on a video or audio document, the browser will try to go to the time the anchor represents. It is worth noting that the part after the #, also known as the fragment identifier, is never sent to the server with the request.
How to use URLs
Any URL can be typed right inside the browser’s address bar to get to the resource behind it. But this is only the tip of the iceberg!
The HTML language — which will be discussed later on — makes extensive use of URLs:
Other technologies, such as CSS or JavaScript, use URLs extensively, and these are really the heart of the Web.
Absolute URLs vs. relative URLs
What we saw above is called an absolute URL, but there is also something called a relative URL. The URL standard defines both — though it uses the terms absolute URL string and relative URL string, to distinguish them from URL objects (which are in-memory representations of URLs).
Let’s examine what the distinction between absolute and relative means in the context of URLs.
The required parts of a URL depend to a great extent on the context in which the URL is used. In your browser’s address bar, a URL doesn’t have any context, so you must provide a full (or absolute) URL, like the ones we saw above. You don’t need to include the protocol (the browser uses HTTP by default) or the port (which is only required when the targeted Web server is using some unusual port), but all the other parts of the URL are necessary.
When a URL is used within a document, such as in an HTML page, things are a bit different. Because the browser already has the document’s own URL, it can use this information to fill in the missing parts of any URL available inside that document. We can differentiate between an absolute URL and a relative URL by looking only at the path part of the URL. If the path part of the URL starts with the «/» character, the browser will fetch that resource from the top root of the server, without reference to the context given by the current document.
Let’s look at some examples to make this clearer.
Examples of absolute URLs
Despite their very technical flavor, URLs represent a human-readable entry point for a website. They can be memorized, and anyone can enter them into a browser’s address bar. People are at the core of the Web, and so it is considered best practice to build what is called semantic URLs. Semantic URLs use words with inherent meaning that can be understood by anyone, regardless of their technical know-how.
Linguistic semantics are of course irrelevant to computers. You’ve probably often seen URLs that look like mashups of random characters. But there are many advantages to creating human-readable URLs:
See also
Data URLs: URLs prefixed with the data: scheme, allow content creators to embed small files inline in documents.
Данная статья описывает Единый локатор ресурсов или Uniform Resource Locators (URLs), объясняет, что это такое, и описывает его структуру.
Введение
Наряду с понятиями гипертекста и протокола HTTP, понятие URL является одной из основных концепций Всемирной паутины. Это механизм, используемый браузерами для получения любого опубликованного во Всемирной сети ресурса.
URL обозначает Uniform Resource Locator. U RL это лишь адрес, который выдан уникальному ресурсу в интернете. В теории, каждый корректный URL ведёт на уникальный ресурс. Такими ресурсами могут быть HTML-страница, CSS-файл, изображение и т.д. На практике, существуют некоторые исключения, когда, например, URL ведёт на ресурс, который больше не существует или который был перемещён. Поскольку ресурс, доступный по URL, а также сам URL обрабатываются веб-сервером, его владелец должен внимательно следить за размещаемыми ресурсами и связанными с ними URL.
Активное обучение
Вот несколько примеров URL:
Каждый из этих URLs могут быть напечатаны в адресной строке браузера, чтобы заставить его загрузить связанную страницу (ресурс).
URL состоит из различных частей, некоторые из которых являются обязательными, а некоторые — факультативными. Рассмотрим наиболее важные части на примере:
http:// это протокол. Он отображает, какой протокол браузер должен использовать. Обычно это HTTP-протокол или его безопасная версия — HTTPS. Интернет требует эти 2 протокола, но браузеры часто могут использовать и другие протоколы, например mailto: (чтобы открыть почтовый клиент) или ftp: для запуска передачи файлов, так что не стоит удивляться, если вы вдруг увидите другие протоколы.
:80 это порт. Он отображает технический параметр, используемый для доступа к ресурсам на веб-сервере. Обычно подразумевается, что веб-сервер использует стандартные порты HTTP-протокола (80 для HTTP и 443 для HTTPS) для доступа к своим ресурсам. В любом случае, порт — это факультативная составная часть URL.
/path/to/myfile.html это адрес ресурса на веб-сервере. В прошлом, адрес отображал местоположение реального файла в реальной директории на веб-сервере. В наши дни это чаще всего абстракция, позволяющая обрабатывать адреса и отображать тот или иной контент из баз данных.
?key1=value1&key2=value2 это дополнительные параметры, которые браузер сообщает веб-серверу. Эти параметры — список пар ключ/значение, которые разделены символом &. Веб-сервер может использовать эти параметры для исполнения дополнительных команд перед тем как отдать ресурс. Каждый веб-сервер имеет свои собственные правила обработки этих параметров и узнать их можно, только спросив владельца сервера.
Примечание: Есть и другие составные части и правила, касающиеся URL, но обычно они не используются ни пользователями, ни разработчика. Поэтому не стоит о них беспокоиться, вам не обязательно их знать, чтобы формировать работоспособные URL.
Как использовать URL
Каждый URL может быть напечатан напрямую в адресной строке браузера, чтобы сразу получить запрошенный ресурс. Но это только вершина айсберга!
Язык HTML — который будет обсуждать позже (en-US) — позволяет активно использовать URL для:
Другие технологии, такие как CSS или JavaScript, также активно используют URL, так что это реально основа веба.
Абсолютные и относительные URL
Все, что мы изучали выше — это абсолютные URL. Но так же существуют и относительные URL. Изучим их.
Обязательные части URL во многом зависят от контекста, в котором используется URL. В адресной строке браузера URL не имеет никакого контекста, так что приходится вводить полный (или абсолютный) URL, такие как мы рассматривали выше. Обычно вам не требуется вводить протокол (браузер подставляет HTTP по умолчанию) и порт (который нужен только в том случае, если сервер использует нестандартный порт), но остальные части URL всё равно необходимы.
Когда URL используется в документе, например в HTML-странице, ситуация отличается. Потому что браузер уже знает URL текущего документа и он может использовать эти сведения для дополнения недостающих частей любого адреса, указанного в документе. Простейший пример относительного URL — указание только адресной части URL. А если адрес в URL начинается с символа «/», браузер запросит ресурс от корня сервера, без отсылки к контексту текущего документа.
Разберём это на примерах.
Примеры абсолютных URL
Полный URL (такой же, как обсуждали в начале статьи)
В этом случае браузер использует тот же протокол, что использовался для загрузки текущего документа.
Это наиболее частый пример использования абсолютного URL в HTML-документе. Браузер использует тот же протокол и то же доменное имя, как у текущего документа. Примечание: не возможно скрыть домен, не скрывая при этом протокол, только вместе.
Примеры относительных URL
Для лучшего понимания следующих примеров, давайте договоримся, что мы обращаемся к URL из документа, который опубликован по адресу: https://developer.mozilla.org/ru/docs/Learn
Поскольку URL не начинается с /, браузер сделает попытку найти документ в поддиректории относительно текущего документа. В данном примере будет запрошен этот URL: https://developer.mozilla.org/ru/docs/Learn/Skills/Infrastructure/Understanding_URLs
Назад по дереву папок
В этом случае, мы используем команду ./ — унаследованную из файловой системы UNIX — чтобы сказать браузеру, что он должен подняться на 1 директорию вверх. Соответственно, здесь мы хотим открыть URL: https://developer.mozilla.org/ru/docs/Learn/./CSS/display, который может быть упрощён до вида: https://developer.mozilla.org/ru/docs/CSS/display
Семантические URL
Помимо своего технического значения, URL представляют собой человеко-читаемые записи о местоположении документов на веб-ресурсе. Они могут быть запомнены и любой может ввести их в адресную строку своего браузера. Веб создавался для людей и распространённой практикой является принцип записи URL, который называется семантические URL. Семантические URL используют в своём составе слова, значение которых может быть понято любым человеком, даже тем, кто не разбирается в технических нюансах.
Семантика, разумеется, плохо распознаётся компьютерами. Вы наверняка видели URL, которые выглядят как куча случайных символов. Но у семантических URL есть много преимуществ:
Следующие шаги
URL-адреса веб-страниц бывают статические и динамические.
С точки зрения SEO предпочтительнее статические ссылки, так как динамические URL имеют ряд недостатков:
Человекопонятный URL (ЧПУ)
Основная ценность ЧПУ состоит в том, что он помогает пользователю:

Проведите SEO аудит сайта, чтобы выявить страницы с плохо составленными URL-адрессами.
Структура URL адреса
URL адрес имеет определенную структуру, которая включает:
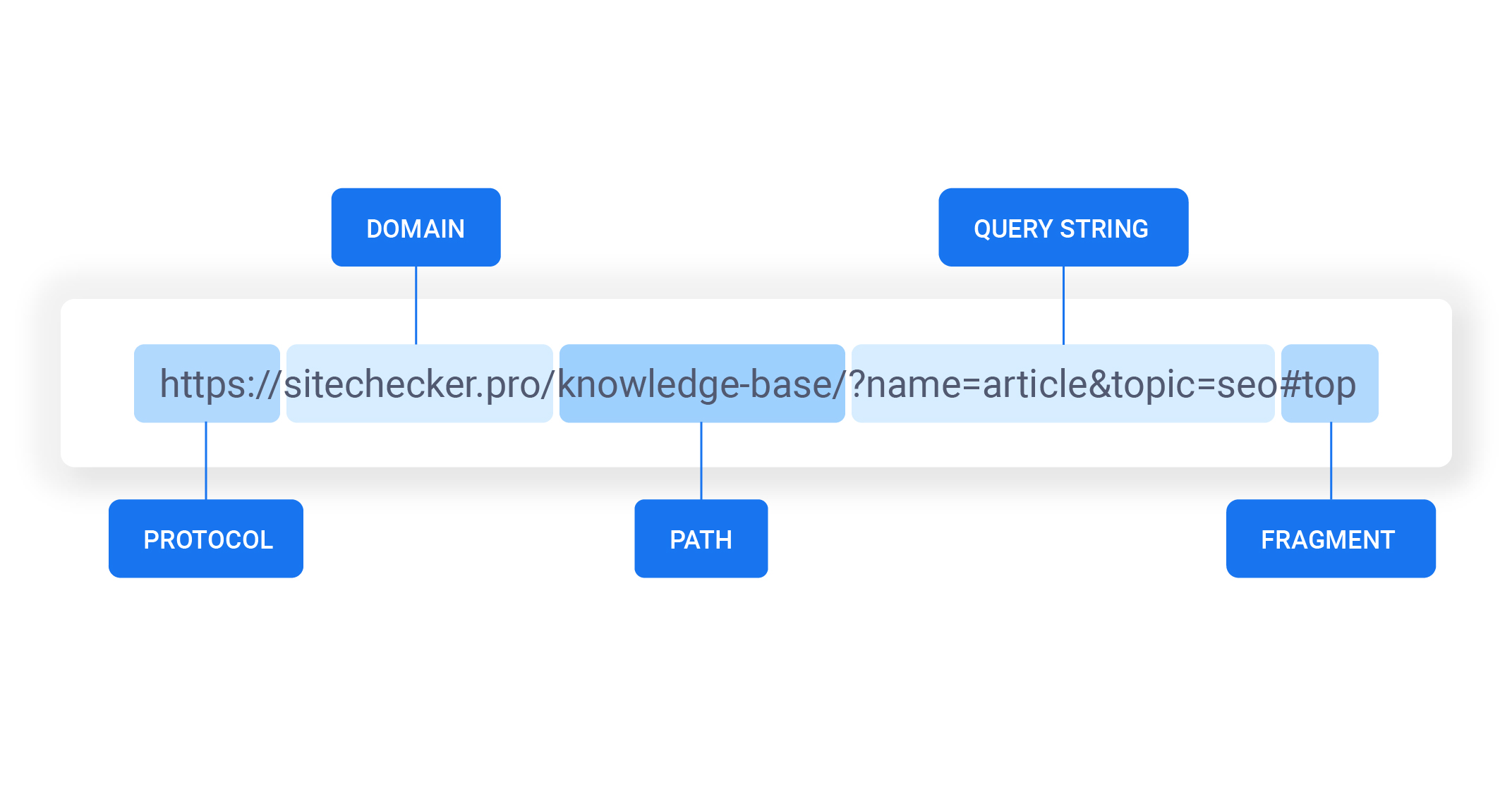
URL был разработан как система для максимально естественного указания на местонахождения ресурсов в сети. Локатор должен был быть легко расширяемым и использовать лишь ограниченный набор ASCII‐символов (к примеру, в URL никогда не применяется пробел). В связи с этим возникла следующая традиционная форма записи URL:
В этой записи:
схема обращения к ресурсу; в большинстве случаев имеется в виду сетевой протокол
имя пользователя, используемое для доступа к ресурсу
пароль указанного пользователя
порт хоста для подключения
уточняющая информация о месте нахождения ресурса; зависит от протокола.
строка запроса с передаваемыми на сервер (методом GET) параметрами. Начинается с символа ?, разделитель параметров — знак &. Пример: ?параметр_1=значение_1&параметр_2=значение_2&параметр3=значение_3
с предшествующим символом #. Якорем может быть указан заголовок внутри документа или элемента. По такой ссылке браузер откроет страницу и переместит окно к указанному элементу. Например, ссылка на этот раздел статьи: https://ru.wikipedia.org/wiki/URL#Структура_URL.
Форматы URL
Для обозначения названий статей обычно используют транслитерацию. Такие адреса легко читаются и понятны для восприятия пользователей.

По такому адресу сразу можно судить, какое содержимое вы увидите на странице. Поисковые системы легко распознают в подобных адресах ключевые слова, что также оказывает положительное влияние на SEO. Если в URL используется транслитерация, становится четко видна структура сайта и, чтобы попасть в нужный раздел, пользователь просто может стереть в адресной строке часть адреса.
Латиница
Латинские URL представляют собой адреса, переведенные на английский язык. Например, вместо «/novosti/» в адресе будет значиться «/news/».
Такой формат УРЛ часто используется для обозначения веб-страниц категорий и рубрик. Этот вариант считается универсальным, так как легко воспринимается пользователями и без труда обрабатывается поисковыми роботами.
Кириллические URL
Такой формат URL чаще всего применяют в кириллических доменах или когда часть адреса не очень длинная.
К их преимуществам относятся:
Однако кириллические URL имеют существенный недостаток: при копировании такого адреса и вставки его в сообщение для отправки кому-либо или вставки в текстовый редактор, вы получите непонятный набор знаков, наподобие:
Это объясняется тем, что запись URL-адресов возможна только определенными символами из разрешенного набора, а символы кириллицы в него не входят. Поэтому адрес, в котором используется кириллица, шифруется, хотя при этом ссылка все равно будет работать.
К минусам кириллических УРЛов можно отнести и трудность для восприятия зарубежными пользователями, привыкшими к латинским символам, а также сложности при чтении адресов этого формата поисковыми роботами (такие URL приходится переводить в понятный для робота вид).
URL-адрес, который мы видим в адресной строке браузера, состоит из нескольких частей:
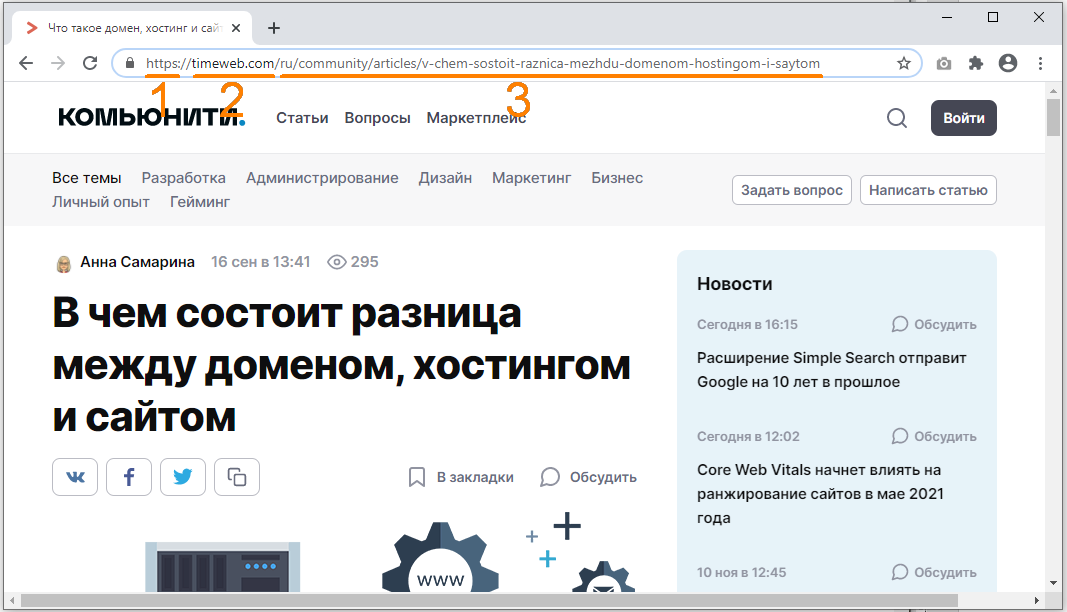
В начале адреса
всегда указан протокол (в некоторых браузерах по умолчанию он может быть скрыт и становится виден при щелчке по адресной строке). Если мы просматриваем веб-страницу, это будет протокол передачи данных «http» или его форма «https» с поддержкой шифрования для установки безопасного соединения. Однако URL может начинаться с других обозначений, например:
Затем указывается путь к странице
, состоящий из каталогов и подкаталогов, который, в свою очередь, включает в себя ее название.
URL также может включать параметры, которые указываются после знака «?» и разделяются символом «&». Пример адреса страницы с результатами поиска по слову «url» в поисковой системе Google:
Конечный компонент URL, который пользователь может увидеть в документах большого объема, состоящих из нескольких разделов, — это якорь, которому предшествует знак решетки «#». Часть адреса после этого знака ссылается на определенный абзац внутри страницы сайта. Пример: если на странице Википедии со статьей «URL» перейти по ссылке «Структура URL» в блоке «Содержание», унифицированный указатель ресурса в адресной строке браузера примет такой вид:
Как скопировать URL
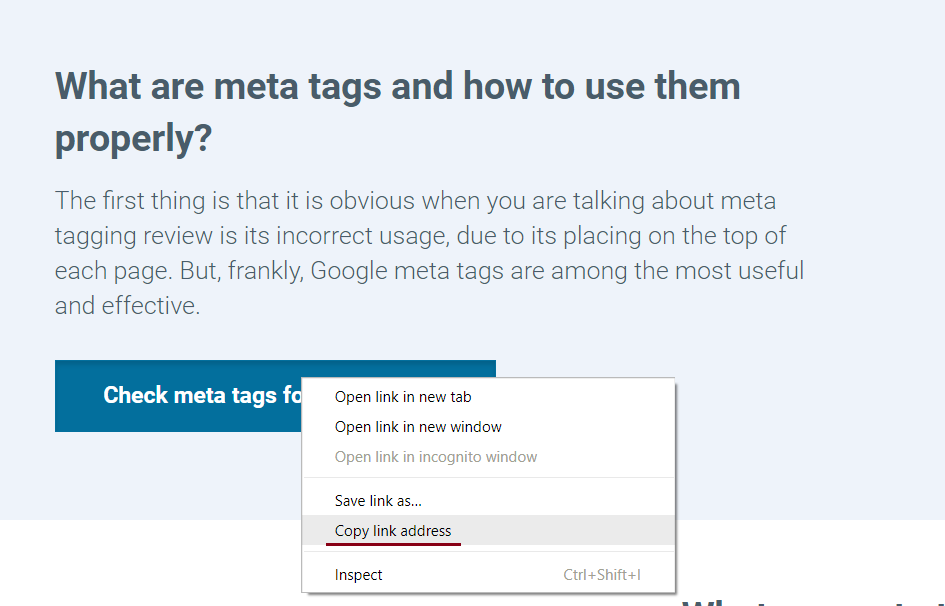
URL адрес имеют не только ресурсы сайта, но также его изображения, файлы и папки. Чтобы получить данные об их URL адресах, вы должны нажать правую кнопку мыши на интересующее вас изображение и выбрать в контекстном меню параметр «Копировать URL изображения».
Если вы желаете узнать URL адрес документа, выполните те же действия, что и при выборе изображения в контекстном меню, но на этот раз воспользуйтесь опцией «Скопировать адрес ссылки».
Скопировав ссылку, вы переносите её в буфер обмена. Также вы можете вставлять её в новую адресную строку, чтобы найти нужный документ, отправить ссылку, прикрепив её к сообщению, или вставить её в существующий текст в своем документе.
Ещё один кардинальный недостаток URL состоит в отсутствии гибкости. Ресурсы во Всемирной паутине и Интернете перемещаются, а ссылки в виде URL остаются, указывая на уже отсутствующие ресурсы. Это особенно болезненно для электронных библиотек, каталогов и энциклопедий. Для решения этой проблемы были предложены постоянные локаторы PURL (англ. Persistent Uniform Resource Locator). В сущности это те же URL, но они указывают не на конкретное место расположения ресурса, а на запись в базе данных PURL, где, в свою очередь, записан уже конкретный URL‐адрес ресурса. При обращении к PURL сервер находит нужную запись в этой базе данных и перенаправляет запрос уже на конкретное местоположение ресурса. Если адрес ресурса меняется, то нет нужды исправлять все бесчисленные ссылки на него — достаточно лишь изменить запись в БД. В настоящий момент эта идея не стандартизирована и не имеет широкого распространения.
История URL адреса
Как и любое другое понятие, URL имеет собственную историю. Сегодня его основная функция – указать конечный сервер, на котором хранится информация. Созданный в 1990 году известным британским изобретателем Тимоти Джоном, первый URL был представлен в Женеве. Раньше он использовался для определения местоположения конечных веб-документов в Интернете. Но разработчики пришли к мысли, что URL адрес может предоставлять пользователям доступ и к другим ресурсам.
Ирина — SEO-эксперт Sitechecker. Она отвечает за категорию и обзоры веб-хостингов. Одержима исследованиями, разработкой и созданием ценного контента.
В чем разница между доменом и URL?
Домен и URL (Uniform Resource Locator) — это два разных понятия, связанных с идентификацией ресурсов в Интернете:
Домен является частью URL и представляет собой идентификатор конкретного сайта, на котором находится ресурс, а URL представляет собой полный адрес, который указывает на местоположение и доступ к ресурсу в сети Интернет, включая протокол, доменное имя и путь к ресурсу.
Стандарт URL использует набор символов US-ASCII. Это имеет серьёзный недостаток, поскольку разрешается использовать лишь латинские буквы, цифры и несколько знаков пунктуации. Все другие символы необходимо перекодировать. Например, перекодироваться должны буквы кириллицы, буквы с диакритическими знаками, лигатуры, иероглифы. Перекодирующая кодировка описана в стандарте RFC 3986 и называется или .
Пример кодирования можно видеть в русскоязычной Википедии, использующей в URL русский язык. Например, строка вида:
Преобразование происходит в два этапа: сначала каждый символ кириллицы кодируется в UTF-8 в последовательность из двух байтов, а затем каждый байт этой последовательности записывается в шестнадцатеричном представлении с предшествующим знаком процента (%):
Все другие символы в URI кодируются.
Зарезервированные символы кодируются в таком соответствии:
Поскольку такому преобразованию подвергаются буквы всех алфавитов, кроме базовой латиницы, то URL со словами подавляющего большинства языков может стать нечитаемым для человека.
Это всё входит в противоречие с принципом интернационализма, провозглашаемого всеми ведущими организациями Интернета, включая W3C и ISOC. Эту проблему призван решить стандарт IRI (англ. Internationalized Resource Identifier) — международных идентификаторов ресурсов, в которых можно было бы без проблем использовать символы Юникода, и которые поэтому не ущемляли бы права других языков. Хотя заранее сложно сказать, смогут ли когда‐либо идентификаторы IRI заменить столь широко используемые URL (и URI в целом).
Примеры URL адресов
Основная часть URL адреса – это доменное имя веб-сайта. Чтобы выбрать правильный адрес для эффективного продвижения сайта в поисковой выдаче, следуйте такому правилу. Идеальный адрес страницы сайта должен быть коротким и релевантным запросу пользователя.
Такой идеальный адрес еще называется человекопонятным URL (ЧПУ, семантический URL). Ниже показаны примеры URL который понятен пользователям и URL который не несет никакой информации ни для пользователя, ни для поисковых систем.
Схемы (протоколы) URL
Общепринятые схемы (протоколы) URL включают:
Экзотические схемы URL:
Схемы URL в браузерах:
Шифрование URL
Часто, скопировав адрес некоторого русскоязычного ресурса, пользователи остаются озадачены тем, что они видят. Набор символов, который они видят, очень сложно идентифицировать. Он совсем не похож на адрес, который находится в адресной строке. Причина в том, что адресные надписи могут быть сформированы только с помощью символов предлагаемого списка. Кириллический алфавит не входит в такой список. Если адрес включает кириллические символы, он будет зашифрован, хотя содержание ссылки и не изменится.
Структура URL сайта должна быть предельно простой. Попробуйте организовать контент так, чтобы URL имели логическую структуру и были понятны для человека (по возможности используйте слова, а не идентификаторы, состоящие из множества цифр)
Справка Search Console
Человекопонятные URL
Поисковые системы рекомендуют создавать дружественные адреса веб-страниц, по которым и пользователи, и поисковые роботы смогут судить, какая информация на этой странице находится. Например, по URL-адресу вида: www.yoursite.net/viewpage.php?page_id=23 понять это невозможно, а адрес www.yoursite.net/contact/ сразу дает представление о содержании страницы. Такие УРЛы называют человекопонятными (ЧПУ).
Кроме того, что они позволяют понять содержание веб-страницы еще до перехода по ссылке, подобные адреса имеют и другие преимущества:
При формировании ЧПУ на своем сайте следует придерживаться определенных правил:

URL был изобретён Тимом Бернерсом-Ли в 1990 году в стенах Европейского совета по ядерным исследованиям (фр. Conseil Européen pour la Recherche Nucléaire, CERN) в Женеве, Швейцария. U RL стал фундаментальной инновацией в Интернете. Изначально URL предназначался для обозначения мест расположения ресурсов (чаще всего файлов) во Всемирной паутине. Сейчас URL применяется для обозначения адресов почти всех ресурсов Интернета. Стандарт URL закреплён в документе RFC 3986. Сейчас URL позиционируется как часть более общей системы идентификации ресурсов URI,
сам термин URL постепенно уступает место более широкому термину URI. Стандарт URL регулируется организацией IETF и её подразделениями.
Кириллические URL-адреса страниц
Возможность использовать кириллические домены и URL-адреса страниц появилась в начале 2000-х годов. Появление кириллических домены и URL связано с внедрением стандарта IDNA (Internationalized Domain Names in Applications), который, в свою очередь, был разработан с целью позволить применение Unicode-символов, включая кириллицу и другие наборы символов, в доменных именах. Это позволяет использовать свои собственные языки и письменности в адресной строке браузера, делая URL-адреса более понятными и удобными для носителей различных языков.
В 2003 году появились первые кириллические домены верхнего уровня (ТLD), которые позволяют использовать кириллические символы в доменных именах. Например, домены .рф и .укр были одними из первых кириллических доменов верхнего уровня, зарегистрированных для России и Украины соответственно. Возможность использования доменов вида .бел для Беларуси была доступна с 2014 года.
В настоящее время кириллические домены и URL-адреса страниц поддерживаются во многих современных браузерах и системах управления контентом (CMS).
Для создания кириллических URL-адресов страниц можно использовать:
Кириллические домены и URL-адреса страниц имеют свои особенности кодировки и отображения, которые следует учитывать:
Вам также будут интересны статьи:
Протоколы передачи данных и взаимодействия в Интернете
Как мы отметили ранее, URL-адрес использует различные протоколы (набор правил и действий) в зависимости от типа ресурса и способа доступа к нему. Наиболее распространенные протоколы (префиксы), которые могут быть использованы в URL-адресах:
Каждый из протоколов предназначен для определенных целей и обеспечивает определенные функции и возможности для передачи данных и взаимодействия в сети. Выбор протокола в URL зависит от того, какой тип ресурса вы хотите получить или какую операцию вы хотите выполнить.
Рекомендации по созданию URL
Соблюдайте указанные выше рекомендации, формируйте человекопонятные URL, чтобы при прочих равных условиях получить преимущество над другими сайтами.